昨天在一台Dell 5810上安装Centos 8 Stream,首先下载ISO文件制作了USB启动盘,在BIOS设置了USB启动后,顺利进入安装界面。
但在选择了 Install CentOS Stream 8-stream 后,并没有进入图形化安装界面,而是出现了下面的错误提示:
......
Nov 23 02:29:16 localhost dracut-initqueue[1065]: Warning: dracut-initqueue timeout - starting timeout scripts
Nov 23 02:29:16 localhost dracut-initqueue[1065]: Warning: dracut-initqueue timeout - starting timeout scripts
Nov 23 02:29:17 localhost dracut-initqueue[1065]: Warning: dracut-initqueue timeout - starting timeout scripts
Nov 23 02:29:17 localhost dracut-initqueue[1065]: Warning: dracut-initqueue timeout - starting timeout scripts
Nov 23 02:29:18 localhost dracut-initqueue[1065]: Warning: dracut-initqueue timeout - starting timeout scripts
Nov 23 02:29:18 localhost dracut-initqueue[1065]: Warning: Could not boot.
Nov 23 02:29:18 localhost systemd[1]: Starting Setup Virtual Console...
Nov 23 02:29:18 localhost systemd[1]: systemd-vconsole-setup.service: Succeeded.
Nov 23 02:29:18 localhost systemd[1]: Started Setup Virtual Console.
Nov 23 02:29:18 localhost systemd[1]: Starting Dracut Emergency Shell...由于在启动过程中发现下面的 TSC_DEADLINE disabled 错误提示,以为是这个提示导致了上面的错误,所以花了很多时间解决这个问题:
Nov 23 02:25:55 localhost kernel: [Firmware Bug]: TSC_DEADLINE disabled due to Errata; please update microcode to version: 0x3a (or later)费了半天力气后,发现 dracut initqueue timeout 跟上面的 TSC_DEADLINE disabled 没关系,完全是两个问题。
最终经过一番搜索,终于在 stackexchange.com的这个问题 中看到了 Anil Thomas 的回答,怀疑和启动时传入的设备名有关。于是在启动到 Dracut Emergency Shell 后,查看 /dev/disk/by-label/ 中的设备文件,输出如下:
dracut:/# ls -l /dev/disk/by-label/
total 0
lrwxrwxrwx 1 root root 10 Nov 23 02:26 CentOS-Stre -> ../../sda4
lrwxrwxrwx 1 root root 10 Nov 23 02:26 data -> ../../sdc1然后重启计算机,在安装界面上,选择 Install CentOS Stream 8-stream,然后按 TAB 键显示启动参数,发现在启动参数中 inst.stage2 所使用的设备名和刚才在 Dracut Emergency Shell 中看到的不一致:
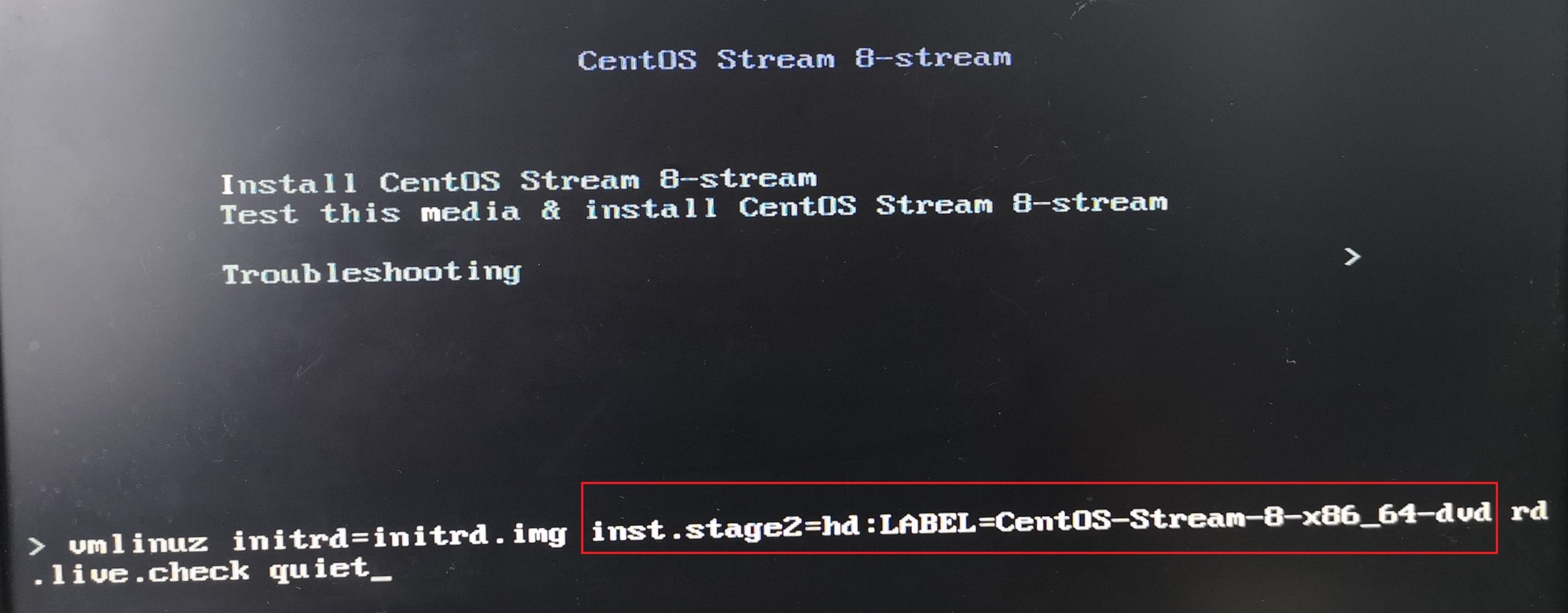
启动参数中的 hd lable是 hd:LABEL=CentOS-Stream-8-x86_64-dvd,但在 /dev/disk/by-label/ 目录中的设备名是 CentOS-Stre,推测是由于某种未知原因,设备名被截短了。于是把启动参数中 hd 参数部分改为 hd:LABEL=CentOS-Stre,修改后按回车键启动安装,果然顺利进入了图形化安装界面!
希望这篇文章能够对遇到此问题的朋友有所帮助!